
# 软件磁盘阵列(Software RAID)
# 什么是 RAID
Redundant Arrays of Inexpensive Disks 简称 RAID,翻译为:容错式链家磁盘阵列。
RAID 通过一种技术(软件或硬件),将多个较小的磁盘整合成为一个较大的磁盘,而且还具有数据保护功能。根据等级不同,整合后的磁盘具有不同的功能,基本常见的 level 有如下几种:
# RAID-0 等量模式 stripe:效能最佳
该模式如果使用相同型号与容量的磁盘来组成时,效果较佳。RAID 将磁盘切出等量的区块(chunk),一般可设置为 4K~1M 之间,当一个文件要写入 RAID 时,该文件会依据 chunk 的大小切割好,再依序放到各个磁盘里。会优先等量存放到各个磁盘上去,比如:有两块磁盘都是 100G,你有一个文件 100M,那么每个磁盘会分到 50MB 的容量,但是如果一块磁盘是 50G,另外一块是 100G,由于是等量,但是由于磁盘小磁盘先被放满,那么其他数据就会落到另一块磁盘上,这种情况下效能就降低了,因为所有压力由一块磁盘承担了。
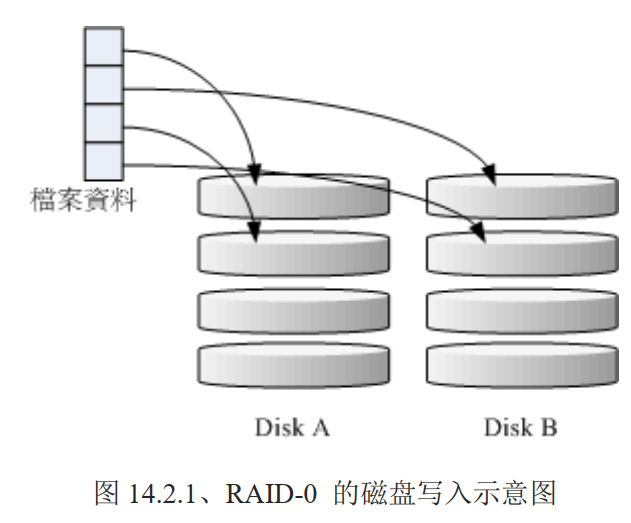
这种模式下,越多的硬盘组成的 RAID-0 理论上效能会越好,因为每块磁盘负责的数据量更低了,但是 只要有任何一块磁盘顺坏,在 RAID 上面的所有数据都会丢失而无法读取。
因为等量分散在每块硬盘上,坏掉一块硬盘,意味着有部分数据丢失了,那么一个文件的部分数据丢失了,不完整了,可能该文件也就损坏了
# RAID-1 映像模式 mirror:完整备份
建议使用相同磁盘容量,最好是一样的磁盘,如果是不同容量的磁盘组成,那么总容量将以最小的那一块为主。
这种模式主要是:让同一份数据,完整的保存在两块磁盘上。比如:100MB 的文件,且目前只有 两块硬盘组成 RAID-1 时,那么每块硬盘上都会写入 100MB 的数据。由于两块磁盘内容一模一样,好像镜子映照出来一样,所以也称为 mirror 模式
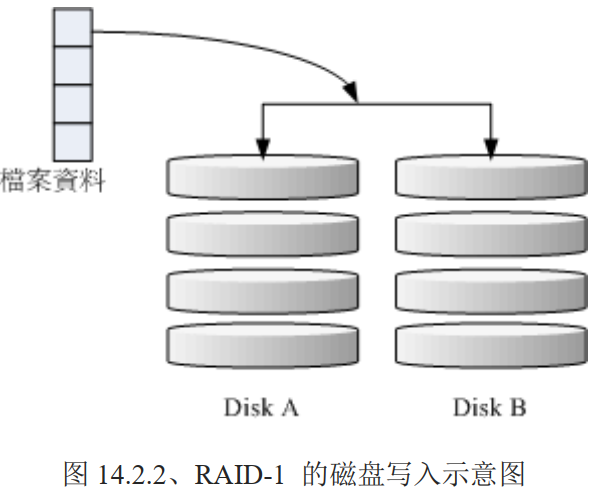
如图,一份数据被写入到两块磁盘中,如果使用软件来做磁盘阵列,那么效能会大大降低,因为只有一个南桥,一份数据要写入两次。如果使用的是 RAID(磁盘阵列卡)时,阵列卡会主动复制一份儿不使用系统的 I/O 总线,效能就还可以。
由于是映像数据,当其中一块硬盘损坏,数据还是完整的。
RAID-1 最大的优点大概就在于数据的备份。用空间换安全。写入效能不佳,但是读取效能还不错,多个 processes 在读取同一份数据时,RAID 会自行取得最佳的读取平衡
# RAID 1+0,RAID 0+1
RAID-0 效能佳,数据不安全。RAID-1 数据安全,但效能不佳。将两者组合起来就形成了:
- RAID 1 + 0:先让两块磁盘组成 RAID 1(共有两组),再让这两组 RAID 1 再组成一组 RAID 0
- RAID 0 + 1:则与上面相反
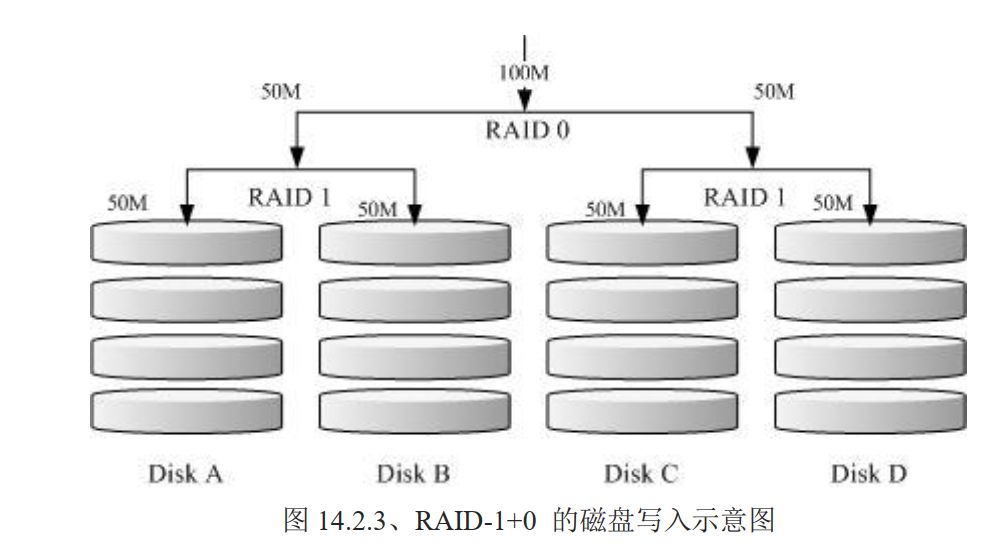
此种方式,最坏的可能性是同时坏掉 b 和 c,也就是 RAID 1 中的其中一块。那么数据都能保证完整。此种方式也是目前存储设备厂商推荐的方法
假设你有 20 快磁盘组成的系统,每两块组成一个 RAID 1,总共有 10 组可以自己复原的系统,再让这 10 组组成一个新的 RAID 0,速度立刻拉升 10 倍了。同时注意:因为每组 RAID 1 是个别独立存在的,因此任何一块磁盘损坏,数据都是从另一块磁盘直接复制过来重建,并不像 RAID5/RAID6 必须要整组 RAID 的磁盘共同重建一块独立的磁盘系统,而且 RAID 1 与 RAID 0 不需要经过计算的(striping),读写效率也比其他的 RAID 等级好太多了,这也是为什么会推荐 RAID1 + 0 方式了
# RAID 5:效能与数据备份的均衡考虑
RAID 5 至少需要三块以上的磁盘才能够组成这种类型的磁盘阵列。数据写入类似 RAID 0,不过每个循环的写入过程中(striping),在每块磁盘还加入一个同位检查数据(Parity),该数据会记录其他磁盘的备份数据,用于当有磁盘损坏时的救援。
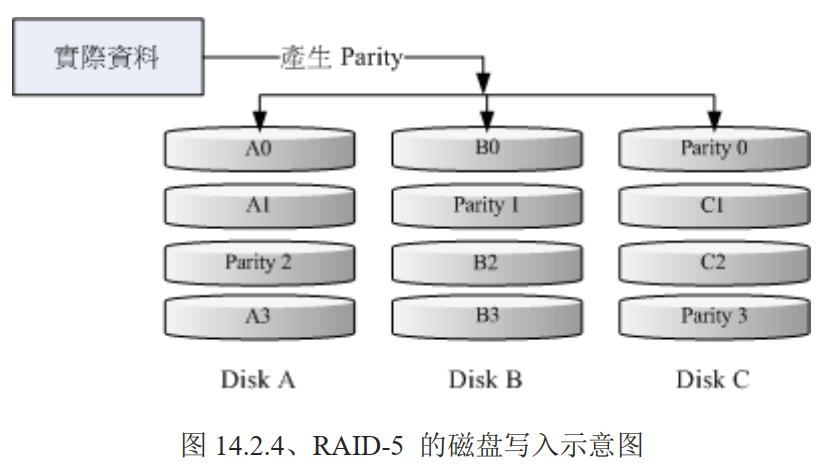
每个循环写入时,都会有部分的同为检查码 parity 被记录,并且记录的同位检查码每次都记录在不同的磁盘,当任何一个磁盘损坏时,可以由其他磁盘的检查码来重建原磁盘内的数据,由于有同位检查码,RAID 5 的总容量会是整体磁盘数量减 1 快磁盘。原本 3 块磁盘,只剩下 3-1 =2 快磁盘的容量。当磁盘损坏数量大于等于 2 块时,整组 RAID 5 的数据就损坏了。因此 RAID 5 预设只能支持一块磁盘损坏的情况
读写效能上的比较:
- 读:由于多快磁盘,效率堪比 RAID-0
- 写:有同位检查码 parity的计算,写入效能与系统的硬件关系较大,尤其当使用软件磁盘阵列时,parity 是通过 CPU 去计算而非专职的磁盘阵列卡,所以写效率需要评估
RAID 5 仅能支持一块磁盘的损坏,因此出现了 RAID 6,RAID 6 使用 2 块磁盘作为 parity 的存储。所以当两块磁盘损坏时,数据还完整
# Spare Disk:预备磁盘的功能
当磁盘阵列损坏时,需要更换新的硬盘,并重建原本的数据。
更换上新的硬盘并顺利启动磁盘阵列后,磁盘阵列会主动重建(rebuild)原本损坏那块磁盘的数据到新的磁盘上,这是磁盘阵列的有点。必过,需要手动插拨硬盘(更换坏掉的硬盘),如果你的系统支持热插播,那么不需要关机就可以完成数据重建
为了让系统可以实时的在坏掉硬盘时主动重建,就需要预备磁盘(spare disk)。就是一块或多块磁盘不包含在原本的磁盘阵列等级中的磁盘,当磁盘阵列中的磁盘顺坏时,则会被主动拉进磁盘阵列中,将坏的磁盘移除磁盘阵列,并重建数据。
同样,如果你的磁盘阵列支持热插拨,拔掉旧硬盘,换上新硬盘,并设置为 spare disk。就更方便了
举例来说“有一个磁盘阵列可允许 16 快磁盘的数量,只有 10 块硬盘(每块 250G),用了 9 快硬盘组成 RAID 5。 1 快硬盘作为 spare disk,那么该磁盘阵列总容量为 (9-1)*250G=2000G。两年后看信号灯才发现坏掉了一块磁盘,那么之前预备的那块 spare disk 被自动拉进磁盘阵列了。 对数据没有任何影响
# 磁盘阵列的优点
如果要磁盘阵列,应该考虑:
- 数据安全与可靠性:不是指网络信息安全,而是当硬件(磁盘)损坏时,数据是否能保证不丢失
- 读写效率:例如 RAID 0 可以加强读写效率,让你的系统 I/O 部分得到改善
- 容量:可以让多块磁盘组合起来,也就意味着单一文件系统可以有相当大的容量
尤其是数据的可靠性与完整性更是使用 RAID 的考虑重点。
各个等级优缺点如下
| 项目 | RAID 0 | RAID 1 | RAID 10 | RAID 5 | RAID 6 |
|---|---|---|---|---|---|
| 最少磁盘 | 2 | 2 | 4 | 3 | 4 |
| 最大容错磁盘(1) | 无 | n-1 | n/2 | 1 | 2 |
| 数据安全性(1) | 完全没有 | 最佳 | 最佳 | 好 | 比 RAID5 好 |
| 理论写入效率(2) | n | 1 | n/2 | < n-1 | < n-2 |
| 理论读取效率(2) | n | n | n | < n-1 | < n-2 |
| 可用容量(3) | n | 1 | n/2 | n-1 | n -2 |
| 一般应用 | 强调效率单数据不重要 | 资料与备份 | 服务器、云系统常用 | 资料与备份 | 资料与备份 |
注意:因为 RAID5/6 读写需要经过 parity 的计算器,因此读写效率不会刚好满足使用的磁盘数量
另外,根据使用情况的不同,一般推荐的磁盘阵列的等级也不同;比如几百 GB 单一大文件数据,会选择在 RAID 6 ,能满足读写需求还有数据完整性保证。如果是在云程序环境中,因为需要确保每个虚拟机能够快速反应及提供数据完整性,因此 RAID5/6 效率较弱的等级是不考虑的,总结来说,大概就剩下 RAID 10 能满足云环境的效率需求了。在某些更特别的环境下,如果搭配 SSD 那么读写效率上会更好
# software、hardware RAID
磁盘阵列分为软件与硬件磁盘阵列
硬件磁盘阵列 hardware RAID 是通过磁盘阵列卡来达成数组的目的。上面有一块专门的芯片处理 RAID 任务,那么很多任务(如 RAID 5 的同为检查码计算)就不会重复消耗原本系统的 I/O 总线。理论上效率更好。另外一般的中高阶磁盘阵列卡都支持热插拨
磁盘阵列卡好的上万,低价的可能只能支持到 RAID 0 与 1,同时还需要磁盘阵列卡的驱动程序,才能使用
由于磁盘阵列有很多优秀的功能,但是很贵,因此就出现了软件仿真磁盘阵列功能,
软件磁盘阵列 software RAID 主要通过软件来仿真数组的任务,因此会耗费较多的系统资源,如 CPU 运算和 IO 总线等资源。由于个人计算机的发展快速,这些限制还不算严重,可以玩一玩软件磁盘阵列
以 CentOS 提供的软件 mdadm 磁盘阵列来说,它会以 partition 或 disk 为磁盘单位,意味着你不需要两块以上的磁盘,只需要有两个以上的分区槽(partition)就能过设计你的磁盘阵列。它支持的等级有 RAID0/1/5 spare disk 等,而且提供的管理机制还能达到类似热插拨的功能,可以在线(文件系统正常使用)进行分区槽的抽换。
硬件磁盘阵列在 Linux 下看起来就是一块实际的大磁盘,因此硬件磁盘阵列文件名为 `/dev/sd[a-p],因为使用到 SCSI 的模块的原因。
软件磁盘阵列时系统仿真的,因此使用的文件名是系统的装置文件,文件名为 /dev/md0 /dev/md1 ...
Intel 的南桥附赠的磁盘阵列功能,在 windows 视乎是完整的磁盘阵列,但是在 Linux 下被视为是软件磁盘阵列的一种,因此如果你有设置过 Intel 的南桥芯片磁盘阵列,那么在 Linux 下会是 /dev/md126、/dev/md127 之类的装置文件名,而他的分区槽是 /dev/md126p1、/dev/md126p2 之类
# 磁盘阵列的设置
很简单,一个指令即可
mdadm --detail /dev/md0
mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK --raid-devices=N --spare-devices=N /dev/sdx /dev/hdx...
选项与参数:
--create:创建 RAID 关键词
--auto=yes:决定建立后面接的软件磁盘阵列装置。也就是 `/dev/md0 、/dev/md1 ...`
--chunk=NK:决定装置的 chunk 大小,也可以当成 stripe 大小,一般是 64K 或 512K
--raid-devices=N:使用几个磁盘(partition)作为磁盘阵列的装置
--spare-devices=N:使用几个磁盘作为备用(spare)装置
--level=[015]:设置这组磁盘阵列的等级。支持很多,不过建议只要用 0、1、5
--detail:后面接的那个磁盘阵列装置的详细信息
2
3
4
5
6
7
8
9
10
11
12
如上语法中,谈到后面接装置名,这些装置文件可以是整块磁盘(如 /dev/sdb),也可以是分区槽(如 /dev/sdb1) 之类,但是这些装置文件名的总数必须要等于 --raid-devices 与 --spare-devices 的个数综合才行。
下面使用测试机创建一个 RAID5 的软件磁盘阵列,磁盘阵列规划如下:
- 利用 4 个 partition 组成 RAID5
- 每个 partition 约 1GB,需确定每个 partition 一样大较佳
- 利用 1 个 partition 设置为 spare disk
- chunk 设置为 256K
- spare disk 的大小与其他 RAID 所需 partition 一样大
- 将此 RAID 5 装置挂载到
/srv/raid目录下
# 磁盘分区
下面进行分区,分区手段参考之前的的章节
# 查看当前磁盘状态
[root@study ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40.8G 0 disk
├─sda1 8:1 0 2M 0 part
├─sda2 8:2 0 1G 0 part /boot
└─sda3 8:3 0 30G 0 part
├─centos-root 253:0 0 10G 0 lvm /
├─centos-swap 253:1 0 1G 0 lvm [SWAP]
└─centos-home 253:2 0 5G 0 lvm /home
sdb 8:16 0 2G 0 disk
sr0 11:0 1 73.6M 0 rom
# 上面发现一快 sda 磁盘,有三个分区,分区大小是 33 G 左右,也就是说还有 7 G 左右可以使用
[root@study ~]# lsblk -ip /dev/sda
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
/dev/sda 8:0 0 40.8G 0 disk
|-/dev/sda1 8:1 0 2M 0 part
|-/dev/sda2 8:2 0 1G 0 part /boot
`-/dev/sda3 8:3 0 30G 0 part
|-/dev/mapper/centos-root 253:0 0 10G 0 lvm /
|-/dev/mapper/centos-swap 253:1 0 1G 0 lvm [SWAP]
`-/dev/mapper/centos-home 253:2 0 5G 0 lvm /home
# 那么下面
[root@study ~]# lsblk -ip /dev/sda
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
/dev/sda 8:0 0 40.8G 0 disk
|-/dev/sda1 8:1 0 2M 0 part
|-/dev/sda2 8:2 0 1G 0 part /boot
`-/dev/sda3 8:3 0 30G 0 part
|-/dev/mapper/centos-root 253:0 0 10G 0 lvm /
|-/dev/mapper/centos-swap 253:1 0 1G 0 lvm [SWAP]
`-/dev/mapper/centos-home 253:2 0 5G 0 lvm /home
# 开始分区,总共需要分出来 5 个 1 g 的分区
[root@study ~]# gdisk /dev/sda
GPT fdisk (gdisk) version 0.8.10
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
# 查看当前 磁盘 的状态
Command (? for help): p
Disk /dev/sda: 85491712 sectors, 40.8 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 67038DBF-B66A-4D0F-92B2-BFBF0744CD1D
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 85491678
Partitions will be aligned on 2048-sector boundaries
Total free space is 20467645 sectors (9.8 GiB) # 空闲扇区
Number Start (sector) End (sector) Size Code Name
1 2048 6143 2.0 MiB EF02
2 6144 2103295 1024.0 MiB 0700
3 2103296 65026047 30.0 GiB 8E00
# 有上面可以看出来,实际上还有 9 g 左右可以使用
Command (? for help): n
Partition number (4-128, default 4):
First sector (34-85491678, default = 65026048) or {+-}size{KMGTP}:
Last sector (65026048-85491678, default = 85491678) or {+-}size{KMGTP}: +1G
Current type is 'Linux filesystem'
Hex code or GUID (L to show codes, Enter = 8300): Fd00
Changed type of partition to 'Linux RAID'
# 上面分区了一个,后面 4 个分区,就不贴出来了
....
Command (? for help): P
Disk /dev/sda: 85491712 sectors, 40.8 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 67038DBF-B66A-4D0F-92B2-BFBF0744CD1D
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 85491678
Partitions will be aligned on 2048-sector boundaries
Total free space is 9981885 sectors (4.8 GiB)
Number Start (sector) End (sector) Size Code Name
1 2048 6143 2.0 MiB EF02
2 6144 2103295 1024.0 MiB 0700
3 2103296 65026047 30.0 GiB 8E00
4 65026048 67123199 1024.0 MiB FD00 Linux RAID
5 67123200 69220351 1024.0 MiB FD00 Linux RAID
6 69220352 71317503 1024.0 MiB FD00 Linux RAID
7 71317504 73414655 1024.0 MiB FD00 Linux RAID
8 73414656 75511807 1024.0 MiB FD00 Linux RAID
# 最后分区好的 5 个分区如上。每个都占用 1G 空间
# 最后保存分区
Command (? for help): w
Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING
PARTITIONS!!
Do you want to proceed? (Y/N): y
OK; writing new GUID partition table (GPT) to /dev/sda.
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot.
The operation has completed successfully.
# 再次确认分区
Command (? for help): p
Disk /dev/sda: 85491712 sectors, 40.8 GiB
Logical sector size: 512 bytes
Disk identifier (GUID): 67038DBF-B66A-4D0F-92B2-BFBF0744CD1D
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 85491678
Partitions will be aligned on 2048-sector boundaries
Total free space is 9981885 sectors (4.8 GiB) # 空闲扇区
Number Start (sector) End (sector) Size Code Name
1 2048 6143 2.0 MiB EF02
2 6144 2103295 1024.0 MiB 0700
3 2103296 65026047 30.0 GiB 8E00
4 65026048 67123199 1024.0 MiB FD00 Linux RAID
5 67123200 69220351 1024.0 MiB FD00 Linux RAID
6 69220352 71317503 1024.0 MiB FD00 Linux RAID
7 71317504 73414655 1024.0 MiB FD00 Linux RAID
8 73414656 75511807 1024.0 MiB FD00 Linux RAID
# 之前空闲扇区是 9.8G,现在还有 4.8G,也有 5 个分区,证明是分区成功了的
# 最后记得分区相关的更新指令,否则使用 lsblk 还是看不到分区出来的 part
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
上面复习了一下分区操作,下面开始配置 RAID
# 配置 RAID
# 确认分区槽
[root@study ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40.8G 0 disk
├─sda1 8:1 0 2M 0 part
├─sda2 8:2 0 1G 0 part /boot
├─sda3 8:3 0 30G 0 part
│ ├─centos-root 253:0 0 10G 0 lvm /
│ ├─centos-swap 253:1 0 1G 0 lvm [SWAP]
│ └─centos-home 253:2 0 5G 0 lvm /home
├─sda4 8:4 0 1G 0 part
├─sda5 8:5 0 1G 0 part
├─sda6 8:6 0 1G 0 part
├─sda7 8:7 0 1G 0 part
└─sda8 8:8 0 1G 0 part
sdb 8:16 0 2G 0 disk
sr0 11:0 1 73.6M 0 rom
# 以 mdadm 建立 RAID
[root@study ~]# mdadm --create /dev/md0 --auto=yes --level=5 --chunk=256K --raid-devices=4 --spare-devices=1 /dev/sda{4,5,6,7,8}
mdadm: /dev/sda5 appears to contain an ext2fs file system
size=1048576K mtime=Sun Oct 27 18:05:52 2019 # 有时候出现这个信息,不用管
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
# 详细的参数说明,查看前面章节,这里使用 {} 将重复的项目简化
# 此外 dsa 5 提示 ext2fs 问题,是抓到之前的 filesystem
# 去人创建,就会删除之前的的旧系统
[root@study ~]# mdadm --detail /dev/md0
/dev/md0: # 装置文件名
Version : 1.2
Creation Time : Sat Feb 29 06:13:57 2020 # 创建 RAID 的时间
Raid Level : raid5 # RAID 等级,这里是 RAID5
Array Size : 3139584 (2.99 GiB 3.21 GB) # 整组 RAID 整组可用容量
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB) # 每块磁盘的容量
Raid Devices : 4 # 组成 RAID 的磁盘数量
Total Devices : 5 # 包含 spare 的总磁盘数量
Persistence : Superblock is persistent
Update Time : Sat Feb 29 06:14:06 2020
State : clean # 目前这个磁盘整理的使用状态
Active Devices : 4 # active 启动的装置数量
Working Devices : 5 # 目前使用此数组的数量
Failed Devices : 0 # 损坏的装置数量
Spare Devices : 1 # 预备磁盘的数量
Layout : left-symmetric
Chunk Size : 256K # chunk 的区块容量
Consistency Policy : resync
Name : study.centos.mrcode:0 (local to host study.centos.mrcode)
UUID : ba4883f9:75e8224b:6961ac93:d16adbf7
Events : 18
Number Major Minor RaidDevice State
0 8 4 0 active sync /dev/sda4
1 8 5 1 active sync /dev/sda5
2 8 6 2 active sync /dev/sda6
5 8 7 3 active sync /dev/sda7
4 8 8 - spare /dev/sda8
# 最后的 5 行数据,是目前 5 快磁盘分区的情况,4 个 active sync,1 个 spare
# RaidDevice 指的是此 RAID 内的磁盘顺序
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
由于磁盘阵列创建需要一些时间,所以最好等待几分钟再使用该指令 mdadm --detail /dev/md0查看磁盘阵列情况,否则有可能看到某些磁盘正在 spare rebuilding 之类的提示
通过以上操作,就创建了一个 RAID5 且含有一块 spare disk 的磁盘阵列。
还可以通过如下的文件来查看系统软件磁盘阵列的情况
[root@study ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda7[5] sda8[4](S) sda6[2] sda5[1] sda4[0]
3139584 blocks super 1.2 level 5, 256k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>
2
3
4
5
6
7
上述属性信息, md0 的两行信息:
第一行:指出 md0 为 raid5,且使用了 sda7、sda6、sda5、sda4 四块磁盘。每个装置后面的中括号中的数字是此磁盘在 RAID 中的顺序(RaidDevice),
sda8[4](s)中的 s 则代表它为 spare 磁盘第二行:此磁盘阵列有 3139584 blocks(每个 block 为 1k),所以总容量为 3GB,使用 readi 5 等级,写入磁盘的小区块 chunk 为 256K,使用 algorithm2 磁盘阵列算法。
[m/n]表示此数组需要 m 个装置,且 n 个装置正常运行。因此这里 需要 4 个装置且 4 个装置正常运作。[UUUU]表示 4 个所需的装置的启动情况,U 表示运作,若为_则表示不正常
# 格式化与挂载使用 RAID
因为涉及到 xfs 文件系统的优化(第 7 章中有讲解到),所以这里参数为:
- srtipe(chunk)容量为 256k, su=256k
- 共有 4 块组成 RAID5,因此容量少一块, sw=3
- 由上面两项计算出数据宽度为 256K*3=768K
所以整体要优化这个 XFS 文件系统就是这样:
[root@study ~]# mkfs.xfs -f -d su=256k,sw=3 -r extsize=768k /dev/md0
meta-data=/dev/md0 isize=512 agcount=8, agsize=98048 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=784384, imaxpct=25
= sunit=64 swidth=192 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=64 blks, lazy-count=1
realtime =none extsz=786432 blocks=0, rtextents=0
# 给该装置挂载到 /srv/raid 目录
[root@study ~]# mkdir /srv/raid
[root@study ~]# mount /dev/md0 /srv/raid/
[root@study ~]# df -Th /srv/raid/
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/md0 xfs 3.0G 33M 3.0G 2% /srv/raid
# 就看到多了一个 /dev/md0 的挂载装置了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 仿真 RAID 错误的救援模式
万一磁盘阵列内的装置异常了,要怎么进行救援,下面进行仿真实践
# 语法
# mdadm 救援方面的语法
mdadm --manage /dev/md[0-9] [--add 装置] [--remove 装置] [--fail 装置]
选项与参数:
--add:将装置加入到该 md 中
--remove:将装置从该 md 中移除
--fail:将某个装置设置为出错状态
2
3
4
5
6
7
# 设置磁盘为错误
让一块磁盘变成错误,然后让 spare disk 自动开始重建
# 先复制一点数据到磁盘阵列中
[root@study ~]# cp -a /etc /var/log/ /srv/raid/
[root@study ~]# df -Th /srv/raid/
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 xfs 3.0G 121M 2.9G 4% /srv/raid
[root@study ~]# du -sm /srv/raid/*
42 /srv/raid/etc
45 /srv/raid/log
# 已经复制过来文件了,并且依据看到使用量了
# 1. 假设 /dev/sda6 这个磁盘出问题了,模拟方式如下
[root@study ~]# mdadm --manage /dev/md0 --fail /dev/sda6
mdadm: set /dev/sda6 faulty in /dev/md0
# 查看状态
[root@study ~]# mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat Feb 29 06:13:57 2020
Raid Level : raid5
Array Size : 3139584 (2.99 GiB 3.21 GB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 4
Total Devices : 5
Persistence : Superblock is persistent
Update Time : Sat Feb 29 07:57:44 2020
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 1 #出错的有一个
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 256K
Consistency Policy : resync
Name : study.centos.mrcode:0 (local to host study.centos.mrcode)
UUID : ba4883f9:75e8224b:6961ac93:d16adbf7
Events : 37
Number Major Minor RaidDevice State
0 8 4 0 active sync /dev/sda4
1 8 5 1 active sync /dev/sda5
4 8 8 2 active sync /dev/sda8
5 8 7 3 active sync /dev/sda7
2 8 6 - faulty /dev/sda6
# 这里 sda6 死掉了,我这里查看信息慢了点,没有看到 state 为 spare rebuilding 状态的信息
# 前面通过 cat /proc/mdstat 看到的是 sda8 是 spare 磁盘,这里已经变成 磁盘整理里面的磁盘了
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda7[5] sda8[4] sda6[2](F) sda5[1] sda4[0]
3139584 blocks super 1.2 level 5, 256k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>
# 可以看到 sda6 死掉了。变成了 F
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 将出错的磁盘移除并加入新磁盘
这里由于是让 sda6 模拟出错,如果是真实的盘要替换,也是如下的流程:
从
/dev/md0数组中移除/dev/sda6磁盘整个 Linux 系统关机,拔出 sda6 这块磁盘,并安装上新的
/dev/sda6磁盘,之后开机将新的
/dev/sda6放入/dev/md0数组中拔出旧的 sda6 磁盘
# 这里我手误写成了 sda7 ,会提示在使用中的不能移除
[root@study ~]# mdadm --manage /dev/md0 --remove /dev/sda7
mdadm: hot remove failed for /dev/sda7: Device or resource busy
# 这里就正常了
[root@study ~]# mdadm --manage /dev/md0 --remove /dev/sda6
mdadm: hot removed /dev/sda6 from /dev/md0
[root@study ~]# mdadm --detail /dev/md0
Number Major Minor RaidDevice State
0 8 4 0 active sync /dev/sda4
1 8 5 1 active sync /dev/sda5
4 8 8 2 active sync /dev/sda8
5 8 7 3 active sync /dev/sda7
# sda6 被移除了
2
3
4
5
6
7
8
9
10
11
12
13
14
- 安装新的
/dev/sda6磁盘
[root@study ~]# mdadm --manage /dev/md0 --add /dev/sda6
mdadm: added /dev/sda6
[root@study ~]# mdadm --detail /dev/md0
Number Major Minor RaidDevice State
0 8 4 0 active sync /dev/sda4
1 8 5 1 active sync /dev/sda5
4 8 8 2 active sync /dev/sda8
5 8 7 3 active sync /dev/sda7
6 8 6 - spare /dev/sda6
2
3
4
5
6
7
8
9
10
11
12
如果你的系统支持磁盘热插拨,还不需要关机,就能完成这里的操作,可以说是不停机完成维护,很强
# 开机自动启动 RAID 并自动挂载
新版 distribution 可能会自动搜索 /dev/md[0-9] 开机时设置好所需要的功能建议还是通过配置文件配置。
/etc/mdadm.conf 是 RAID 的配置文件。只要知道 /dev/md0 的 UUID 就可以完成配置
[root@study ~]# mdadm --detail /dev/md0 | grep -i uuid
UUID : ba4883f9:75e8224b:6961ac93:d16adbf7
# UUID 是想系统注册的 UUID 标识
# 配置 mdadm.conf
[root@study ~]# vim /etc/mdadm.conf
ARRAY /dev/md0 UUID=ba4883f9:75e8224b:6961ac93:d16adbf7
# RAID 装置 UUID
# 设置开机自动挂载并测试
[root@study ~]# blkid /dev/md0
/dev/md0: UUID="319f3d68-a144-4d9a-9a83-c83b4a26b98f" TYPE="xfs"
[root@study ~]# vim /etc/fstab
# UUID=319f3d68-a144-4d9a-9a83-c83b4a26b98f /srv/raid xfs 0 0
UUID=319f3d68-a144-4d9a-9a83-c83b4a26b98f /srv/raid xfs defaults 0 0
# 记得上述一定要仔细,这里卸载后,再挂载就提示有问题,检查后发现,少了一个 defaults 项
# 否则直接重启的话,有可能就启动不了了
[root@study ~]# umount /dev/md0; mount -a
mount: wrong fs type, bad option, bad superblock on /dev/md0,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so.
# 修改后就正常了
[root@study ~]# umount /dev/md0
[root@study ~]# mount -a
[root@study ~]# df -Th /srv/raid/
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 xfs 3.0G 121M 2.9G 4% /srv/raid
[root@study ~]# reboot # 重启后,再查看是否自动挂载了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 关闭软件 RAID(重要)
除非你未来要使用这块 software RAID 的 /dev/md0;否则请关闭它
因为:因为这是练习机,后续不会用,另外,它使用了 /dev/sda{4,5,6,7,8} 分区,如果只是将 /dev/md0 卸载,然后忘记关闭 RAID,结果就是在重新分区 /dev/sdaX 时可能会出现一些莫名其妙的错误
关闭步骤如下
# 1. 卸载且删除配置文件与这个 /dev/md0 有关的设置
[root@study ~]# umount /srv/raid/
[root@study ~]# vim /etc/fstab
# 2. 覆盖掉 RAID 的 metadata 以及 XFS 的 superblock,再关闭 /dev/md0
[root@study ~]# dd if=/dev/zero of=/dev/md0 bs=1M count=50
# 这一步很危险;笔者刚刚发现执行 stop,提示找不到 /dev/md0
# 找到问题是在 vim /etc/mdadm.conf 中 ARRAY 写错了,导致开机没有加载
# 然后修改之后,把 fstab 中增加上,再重启,就开不了机了,本想是重试这里的正常卸载
# 谁知道,上面吧 /dev/md0 数据擦除了,导致启动不了系统
# 后来想到前面讲解过怎么进入救援模式,再编辑 fstab 文件,去掉对 /dev/md0 的挂载配置,就好了
# 重启后,在执行下面的指令就正常了
[root@study ~]# mdadm --stop /dev/md0
mdadm:stopped /dev/md0
[root@study ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: <none> # 不存在任何数组装置
# 在去掉这里的配置就可以了
[root@study ~]# vim /etc/mdadm.conf
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
上面使用 dd 是因为 RAID 的相关数据会存一份在磁盘中,如果只是把配置文件去掉了,但是分区槽没有重新规划过,那么重启后,系统还是会将这块磁盘阵列建立起来,只是名称可能会改变成 /dev/md127
所以,记得上述的步骤,但是不要错误的 dd 到了其他磁盘,这个很严重的