# 什么是存储过程
# 数据库编程
写 SQL 脚本,数据库把它编译成二进制代码,
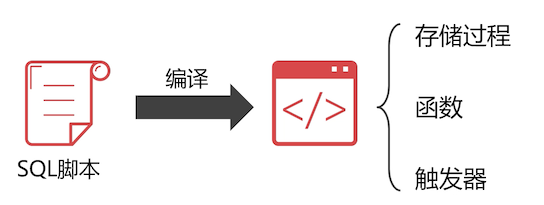
存储过程:不能写在 SQL 语句中调用,只能单独调用。
函数:是一个特殊的存储过程,只能查询并返回数据;不能单独调用
如之前的各种函数,
now()等触发器:一种特殊的存储过程;不需要调用,写好触发条件,会自动触发
这里只是了解,但是结论是:放弃使用他们;
在银行中可能会常用到:比如国外的花旗银行,他们 不想对外暴露表结构,从而编写了大量的存储过程(就如同我们提供接口),外部(衍生的第三方业务;或则是外包出去的功能模块?)带上对应的参数调用即可。这样就能很好的保护他们的数据表
# 存储过程的优点
存储过程是编译过的 SQL 脚本,所以执行速度非常快
- 不用去校验 SQL 语法
- 不用再次编译
实现了 SQL 编程,可以降低锁表的时间和锁表的方位
在存储过程中可以定义变量,把查询出来的结果保存,利用来计算;
比如子查询就是,查询出来的数据无法定义变量影响,变成一个相关子查询,导致锁表数据多。
先查询出来结果,再以变量的形式拼成 SQL,就不用锁表那么多了
对外封装了表结构,提升了数据库的安全性
# 编写存储过程案例
根据部门名称,查询部门用户信息。
CREATE
DEFINER = CURRENT_USER PROCEDURE `p1`(IN p_dname varchar(20))
BEGIN
SELECT e.id, e.ename, e.sex, e.married, j.job
FROM t_emp e
JOIN t_dept d ON e.dept_id = d.id
join t_job j on e.job_id = j.id
where d.dname = p_dname;
END;
-- DEFINER :定义
-- CURRENT_USER:哪些用户可以使用,比如 `root`@`%`
-- PROCEDURE:声明为存储过程
-- 后面是过程的名称,和定义入参
-- 调用存储过程
call p1('零售部');
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
上面是一个简单的案例,这里来一个更加复杂的案例:插入实习员工数据的时候,如果是男性,就分配到网商部实习;如果是女性,就分配到零售部实习
-- 在这之前,先增加一个实习的职位
INSERT INTO neti.t_job (id, job) VALUES (9, '实习生');
CREATE
DEFINER = CURRENT_USER PROCEDURE `p2`(in p_wid varchar(20),
in p_ename varchar(20),
in p_sex char(1),
in p_marred boolean,
in p_education tinyint,
in p_tel varchar(11))
BEGIN
-- 定义一个变量,保存部门编号
declare dept_id int;
-- 条件判断
case
when p_sex = '女' then
set dept_id = 3; -- 然后赋值
else
set dept_id = 4;
end case;
insert into t_emp(wid, ename, sex, married, education, tel, dept_id, hiredate, job_id, `status`)
values (p_wid, p_ename, p_sex, p_marred, p_education, p_tel, dept_id, curdate(), 9, 1);
END;
call p2('TE0023', '陈婷婷', '女', false, 1, '12345678999');
call p2('TE0024', '陈火', '男', false, 1, '12345678900');
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
存储过程这些在 DataGrip 中英文名称叫 routines,官方名称也是这个。汉化含义是:例程