
# 进程管理
为什么进程管理这么重要?是因为:
- 我们在操作系统时的各项工作都是经过某个 PID 来达成的(包括你的 bash 环境),因此,能不能进行某项工作,与该进程的权限有关
- 如果你的 LInux 是个很忙碌的系统,当整个系统资源要被使用光的时候,你是否能够找出最耗资源的哪个进程,然后删除该进程,让系统恢复正常?
- 由于某个程序写的不好,导致产生一个有问题的进程在内存中,如何找出它,将它移除呢?
- 如果有 5、6 项工作在系统中运行,但其中有一项工作才是最重要的,该如何让那一项重要的工作被最优先执行?
以上几点,在系统使用中都是很重要且常见的问题
# 进程的观察
# ps:将某个时间点的进程运行情况截取下来
ps aux # 观察系统所有的进程数据
ps -l # 观察与当前终端机相关的进程
ps -lA # 观察系统所有的进程数据(显示内容项同 ps -l 的项一样,只不过是系统所有进程)
ps axjf # 连同部分进程树状态
选项与参数:
-A:所有的 process 都显示出来,与 -e 具有同样的效果
-a:不与 terminal 有关的所有 process
-u:有效使用者(effective user)相关的 process
x:通常与 a 一起使用,可列出完整信息
输出格式规划:
l:较长、较详细的将该 PID 的信息列出
j:工作的格式(jobs format)
-f:做一个更为完整的输出
2
3
4
5
6
7
8
9
10
11
12
13
14
ps 指令的 man page 不太好查阅,不同的 Unix 都使用 ps 来查阅进程状态,为了符合不同版本的需求,该 man page 写的非常庞大,因此建议你有两个选择:
- 只能查询自己 bash 进程的
ps -l - 可以查询所有系统运行的进程
ps aux
# 仅查看自己的 bash 相关进程:ps -l
# 范例 1: 将目前属于您自己这次登录的 PID 与相关信息列出来(只与自己的 bash 有关)
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 29260 28796 0 80 0 - 57972 do_wai pts/0 00:00:00 su
4 S 0 29473 29260 0 80 0 - 29090 do_wai pts/0 00:00:00 bash
0 R 0 30444 29473 0 80 0 - 12407 - pts/0 00:00:00 ps
# 前面三项,最初是用了普通账户登录的,使用了 su - 切换到了一个 bash
2
3
4
5
6
7
这里列出的只是与你操作环境 bash 有关的进程,没有延伸到 systemd(后续交代):
- F:进程旗标(process flags),说明这个进程的总结权限,常见的号码有:
- 4:表示此进程的权限为 root
- 1:则表示此子进程仅进行 复制(fork)而没有实际执行(exec)
- S:进程状态(STAT),主要状态有:
- R(Running):正在运行中
- S(Sleep):该程序目前正在睡眠状态(idle),但可以被唤醒(signal)
- D:不可被唤醒的睡眠状态,通常该程序可能在等待 I/O 的情况
- T:停止状态(stop),可能是在工作控制(背景暂停)或除错(traced)状态
- Z(Zombie):僵尸状态,进程已终止但却无法被移除至内存外
- UUID/PID/PPID:代表此进程被该 UID 所拥有、进程的 PID 、此进程的父进程 PID
- C:代表 CPU 使用率,单位为百分比
- PRI/NI:Priority/Nice 的缩写,代表此进程被 CPU 所执行的优先级,数值越小表示该进程越快被 CPU 执行。详细的 PRI 与 NI 将在下一小节讲解
- ADDR/SZ/WCHAN:都与内存有关
- ADDR:kernel function,该进程在内存的哪个部分,如果是 running 的进程,一般会显示
- - SZ:该进程用掉多少内存
- WCHAN 该进程是否运行中,若为
-表示正在运行中
- ADDR:kernel function,该进程在内存的哪个部分,如果是 running 的进程,一般会显示
- TTY:登陆者的终端机位置,若为远程登录则使用动态终端接口(pts/n)
- TIME:使用掉的 CPU 时间。注意:是此进程实际花费 CPU 运行的时间
- CMD:command 的缩写,此进程的触发程序指令
如上列出的信息表示, bash 的程序属于 UID 为 0 的使用者,状态是睡眠(sleep),他睡眠是因为他触发了 ps(状态为 R,run)的原因,ps 的 PID=30444,优先执行顺序为 80,下达 bash 所取得的终端机接口为 pts/0,运行状态为 do_wai
# 观察系统所有进程:ps aux
[root@study ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.5 128372 6988 ? Ss 21:14 0:01 /usr/lib/systemd/systemd --switched-root --system --deseriali
root 2 0.0 0.0 0 0 ? S 21:14 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 21:14 0:00 [kworker/0:0H]
...
root 27082 0.0 0.1 51752 1716 pts/2 R+ 21:41 0:00 ps aux
2
3
4
5
6
7
8
会发现 ps -l 与 ps aux 显示的项目也不一样
- USER:该 process 属于哪个使用者账户
- PID:进程标识符
%CPU:该进程使用掉的 CPU 资源百分比%MEM:占用的虚拟内存(KBytes)- RSS:占用的固定内存(KBytes)
- TTY:在哪个终端机上面运行?
?:与终端机无关tty1-tty6:本机上登录的pts/0等:是由网络连接进入的进程
- STAT:目前的状态,与
ps -l中的状态相同含义 - START:该进程被触发启动时间(如果太久不会显示具体时间)
- TIME:该进程实际使用 CPU 运行的时间
- COMMAND:进程执行的指令
一般来说,ps aux 会按照 PID 的顺序来排序显示。
# 范例 3:以范例 1 的显示内容,显示出所有的进程
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 25710 1956 0 80 0 - 57972 do_wai pts/2 00:00:00 su
4 S 0 25917 25710 0 80 0 - 29090 do_wai pts/2 00:00:00 bash
0 R 0 32189 25917 0 80 0 - 12407 - pts/2 00:00:00 ps
[root@study ~]# ps -lA
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 80 0 - 32093 ep_pol ? 00:00:01 systemd
1 S 0 2 0 0 80 0 - 0 kthrea ? 00:00:00 kthreadd
1 S 0 4 2 0 60 -20 - 0 worker ? 00:00:00 kworker/0:0H
1 S 0 6 2 0 80 0 - 0 smpboo ? 00:00:00 ksoftirqd/0
1 S 0 7 2 0 -40 - - 0 smpboo ? 00:00:00 migration/0
1 S 0 8 2 0 80 0 - 0 rcu_gp ? 00:00:00 rcu_bh
1 R 0 9 2 0 80 0 - 0 - ? 00:00:01 rcu_sched
# 会发现,与 ps -l 显示类似,不过显示的是系统的所有进程
# 范例 4:列出类似进程树的进程显示
[root@study ~]# ps axjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
0 2 0 0 ? -1 S 0 0:00 [kthreadd]
2 4 0 0 ? -1 S< 0 0:00 \_ [kworker/0:0H]
2 6 0 0 ? -1 S 0 0:00 \_ [ksoftirqd/0]
1 1269 1269 1269 ? -1 Ss 0 0:00 /usr/sbin/sshd -D
1269 1922 1922 1922 ? -1 Ss 0 0:01 \_ sshd: mrcode [priv]
1922 1932 1922 1922 ? -1 S 1000 0:09 | \_ sshd: mrcode@pts/0,pts/1
1932 1934 1934 1934 pts/0 1934 Ss+ 1000 0:00 | \_ -bash
1932 1939 1939 1939 ? -1 Ss 1000 0:00 | \_ /usr/libexec/openssh/sftp-server
1932 1941 1941 1941 pts/1 2573 Ss 1000 0:00 | \_ -bash
1941 2573 2573 1941 pts/1 2573 S+ 1000 0:04 | | \_ top
1932 7742 7742 7742 ? -1 Ss 1000 0:00 | \_ bash -c export LANG="en_US.UTF-8";export LANGUAGE="en_US.
7742 7789 7742 7742 ? -1 S 1000 0:00 | \_ sleep 1
1269 1926 1926 1926 ? -1 Ss 0 0:01 \_ sshd: mrcode [priv]
1926 1950 1926 1926 ? -1 S 1000 0:09 \_ sshd: mrcode@pts/2,pts/3
1950 1956 1956 1956 pts/2 7790 Ss 1000 0:00 \_ -bash
1956 25710 25710 1956 pts/2 7790 S 0 0:00 | \_ su -
25710 25917 25917 1956 pts/2 7790 S 0 0:00 | \_ -bash
25917 7790 7790 1956 pts/2 7790 R+ 0 0:00 | \_ ps axjf
1950 2009 2009 2009 ? -1 Ss 1000 0:00 \_ /usr/libexec/openssh/sftp-server
1950 2012 2012 2012 pts/3 2574 Ss 1000 0:00 \_ -bash
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
看上面 PPID 为 1269 的那一行开始,我这里使用了 ssh 远程链接,用的是 mrcode 账户,登录成功后,获得了一个 bash 环境,后面我使用了 su - 指令切换到了 root 的 bash 环境,然后执行了刚刚的 ps axjf 指令。这样就比较清楚了。
还可以通过 pstree 指令来显示进程树,不过貌似没有这么详细
# 范例 5:找出与 cron 和 rsyslog 这两个服务有关的 PID 号码
[root@study ~]# ps aux | egrep '(cron|rsyslog)'
root 1273 0.0 0.3 215672 3652 ? Ssl 21:15 0:00 /usr/sbin/rsyslogd -n
root 1285 0.0 0.1 126288 1696 ? Ss 21:15 0:00 /usr/sbin/crond -n
root 4838 0.0 0.0 9096 932 pts/2 R+ 21:58 0:00 grep -E --color=auto (cron|rsyslog)
# 对于上面为什么要使用 egrep,在第 11 章,延伸正则表示法中有介绍。
2
3
4
5
6
# 僵尸进程 zombie
僵尸 zombie:该进程以及执行完毕或则是因故应该要终止了,但是该进程的父进程却无法完整的将该进程结束掉,而造成哪个进程一直在内存中。
在进程中它的标识是在 CMD 后面有 <defunct> 标识,例如下面这样
apache 8683 0.0 0.9 83383 9992 ?Z 14:33 0:00 /usr/sbin/httpd<defunct>
当系统不稳定时,容易造成僵尸进程,可能是因为程序有问题,或则是使用者的操作习惯不良等。
发现有僵尸进程时,应该找出来,分析原因,否则有可能一直产生僵尸进程
事实上,通常僵尸进程都已经无法管控,而直接交给 systemd 程序来负责了,偏偏 systemd 是系统第一个执行的程序,它是所有程序的父程序,无法杀掉该程序(杀掉它,系统就死了),所以,经过一段时间后,系统无法通过核心非经常性的特殊处理来将该进程删除时,那只有重启机器了
# top:动态观察进程的变化
ps 可以显示一个时间点的进程状态,而 top 则可以持续的侦测进程运行状态
top [-d 数字] | top [-bnp]
选项与参数:
-d:后面可以接秒数,整个进程画面更新的秒数,预设是 5 秒更新一次
-b:以批次的方式执行 top,还有更多的参数可以使用(莫名其妙啊,啥参数?),通常会搭配数据流重导向来将批次的结果输出为文件
-n:与 -b 搭配,需要进行几次 top 的输出
-p:指定某些 PID 来进行观察
在 top 执行过程中可以使用的按键指令:
?:显示在 top 中可以输入的按键指令
P:以 CPU 的使用资源排序显示
M:以 Memory 的使用资源排序显示
N:以 PID 排序
T:由该进程使用 CPU 时间累积(TIME+)排序
k:给予某个 PID 一个信号(signal)
r:给予某个 PID 重新制定一个 nice 值
q:离开 top 软件的按键
E:切换单位显示,比如从 KB 切换为 G 显示
c:切换 COMMAND 的信息,name/完成指令
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
top 的功能太多,可用的按键也很多,可以参考 man top 的内部文件说明,上面只是列出常用的选项
# 范例 1:每两秒更新一次 top,观察整体信息
[root@study ~]# top -d 2
top - 22:20:11 up 1:05, 4 users, load average: 0.52, 0.53, 0.52
Tasks: 186 total, 2 running, 184 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.7 us, 9.7 sy, 0.0 ni, 82.1 id, 0.0 wa, 0.0 hi, 0.5 si, 0.0 st
KiB Mem : 1190952 total, 428928 free, 402624 used, 359400 buff/cache
KiB Swap: 1048572 total, 1048572 free, 0 used. 632160 avail Mem
# <<< 如果按下 k 或 r 时,有相关的提示在这里出现
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1699 gdm 20 0 2947388 136736 61224 S 0.5 11.5 0:04.00 gnome-shell
1932 mrcode 20 0 161324 3016 1296 S 0.5 0.3 0:17.28 sshd
1950 mrcode 20 0 161324 3028 1296 S 0.5 0.3 0:17.41 sshd
2573 mrcode 20 0 162820 3068 1576 S 0.5 0.3 0:07.43 top
1 root 20 0 128372 6988 4196 S 0.0 0.6 0:01.67 systemd
2
3
4
5
6
7
8
9
10
11
12
13
14
top 的信息基本上分为两个区域,上面 6 行,和下面的列表
第一行信息:top -
目前开机时间:22:20:11 这个
开机到目前为止所经过的时间:up 1:05 这个
已经登录系统的用户人数:4 users
系统在 1、5、15 分钟的平均工作负载
在第 15 章谈到过 batch 工作方式负载小于 0.8 就是这里显示的值了。
表示的是,系统平均要负责运行几个进程,这里是三个值,也就是对应平均 1/5/15 分钟
越小达标系统越空闲,若高于 1 ,那么你的系统进程执行太频繁了
第二行:tasks
显示的是目前进程的总量与各个状态(running、sleeping、stopped、zombie)的进程数量
如果发现有 zombie 进程的话,就需要找下是哪个进程变成了僵尸进程了
第三行:
$CpusCPU 整体负载,每个项目可使用 ? 查询。
需要特别注意的是 wa 项,表示 I/O wait,通常系统变慢,都是 I/O 产生的问题比较大,需要特别注意该项占用的 CPU 资源,如果是多核 CPU,可以按下数字键「1」来切换成不同 CPU
第四行和第五行
目前的物理内存与虚拟内存(Mem/Swap)的使用情况。要注意的是 swap 的使用量要尽量的少,如果 swap 被大量使用,表示系统的物理内存不足
第六行:当在 top 程序中输入指令时,显示状态的地方
下面的列表部分大部分都见过了,下面再列出含义:
- PID:进程 ID
- USER:进程所属使用者
- PR(priority):进程优先执行顺序,越小越早被执行
- NI(nice):与 PR 有关,越小越早被执行
%CPU:CPU 使用率%MEM:内存使用率TIME+:CPU 使用时间的累加
top 预设使用 CPU 使用率 %CPU作为排序的重点,如果想要使用内存使用率排序,可以按下 M 键,要离开按下 q 键
# 范例 2:将 top 的信息进行 2 次,然后将结果输出到 /tmp/top.txt
[root@study ~]# top -b -n 2 > /tmp/top.txt
# 这里的结果就是,写入了执行 2 次的结果信息。是追加写入的
2
3
由于只有一屏显示,所以当你要观察的进程没有排序到最前面的时候,还可以单独观察该线程
# 范例 3:我们自己的 bash PID 可以由 $$ 变量取得,使用 top 持续观察该 PID
[root@study ~]# top -d 2 -p $$
top - 22:53:55 up 1:39, 2 users, load average: 0.59, 0.28, 0.32
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.1 us, 4.6 sy, 0.0 ni, 92.8 id, 0.0 wa, 0.0 hi, 0.5 si, 0.0 st
KiB Mem : 1190952 total, 435612 free, 392456 used, 362884 buff/cache
KiB Swap: 1048572 total, 1048572 free, 0 used. 642448 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9051 root 20 0 116472 3172 1780 S 0.0 0.3 0:00.04 bash
2
3
4
5
6
7
8
9
10
就只显示着一个程序给你看了,还可以修改 NI 值
# 范例 4:上题的 NI 指是 0,把它修改成 10
# 在上题的 top 画面中按下 r 键出现下面的提示
PID to renice [default pid = 9051] 5501 # 输入要修改的 PID
Renice PID 9051 to value 10 # 输入要修改的 nice 值
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9051 root 30 10 116472 3172 1780 S 0.0 0.3 0:00.04 bash
# 会发现 NI 值已经修改了
2
3
4
5
6
7
8
如果想要找出最耗 CPU 资源的进程时,大多使用 top 指令,然后以 CPU 使用资源来排序(-p)
# pstree
pstree [-AIU] [-up]
选项与参数:
-A:各进程之间的连接以 ASCII 字符来连接
-U:各进程之间的连接以万国码的字符来连接。在某些终端机接口下可能会有错误
-p:并同时列出每个 process 的 PID
-u:并同时列出每个 process 的所属账户名称
2
3
4
5
6
7
# 范例 1:列出目前系统上所有的进程树的相关性
[root@study ~]# pstree -A
systemd-+-ModemManager---2*[{ModemManager}] # ModenManager 与其子进程
|-NetworkManager---2*[{NetworkManager}]
|-2*[abrt-watch-log]
|-abrtd
|-accounts-daemon---2*[{accounts-daemon}]
....
|-sshd---sshd---sshd-+-bash---su---bash---pstree # 我们指令执行的相依性
| |-bash---top
| |-bash
| `-sftp-server
# 看下这个相依性,差不多就是登陆之后,在 su 切换账户之后,执行的
# 范例 2:同时显示出 PID 与 users
[root@study ~]# pstree -Aup
systemd(1)-+-ModemManager(871)-+-{ModemManager}(881)
| `-{ModemManager}(891)
|-NetworkManager(935)-+-{NetworkManager}(941)
| `-{NetworkManager}(945)
|-abrt-watch-log(856)
|-sshd(1269)---sshd(7771)---sshd(7779,mrcode)-+-bash(3239)---sleep(3263)
| |-bash(7780)---su(8985,root)---bash(9051)---pstree(3264)
| |-bash(7835)---top(8102)
| `-sftp-server(7833)
# 可以看到 sshd 登录的 PID 是 7779 ,用 mrcode 账户登录的。后续用 su 切换到了 root,这个时候新开了一个进程 7780 的 bash
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
用 pstree 来找相关性,同时使用 -A 来让连线不断开。默认的 Unicode 连线有可能出现断线,整体画面显示错位的问题
由 pstree 的输出我们可以知道,所有的进程都是依附在 systemd 程序下面的,systemd 的进程 ID 是 1 号,是 LInux 核心主动运行的第一个程序
之前讲解遇到僵尸进程为啥要重启,因为 systemd 要重启,那么就相当于重启系统了
# 进程的管理
进程相互管理是通过一个信号(signal)去告知该进程你要它做什么。信号可以通过 man 7 signal 查阅,主要信号代号与名称含义如下:
| 代号 | 名称 | 含义 |
|---|---|---|
| 1 | SIGHUP | 启动被终止的进程,可让该 PID 重新读取自己的配置文件,类似重新启动 |
| 2 | SIGINT | 相当于用键盘输入 ctrl + c 来终端一个进程的运行 |
| 9 | SIGKILL | 强制终端一个进程的运行,如果该进程进行到一半,那么尚未完成的部分可能会有半成品产生,类似 vim 会有 .filename.swp 保留下来 |
| 15 | SIGTERM | 以正常的结束进程来终止该进程。由于是正常的终止,所以后续的动作会将他完成。不过,如果该进程已经发生问题,就无法使用正常的方法终止时,输入该 signal 也是没有用的 |
| 19 | SIGSTOP | 相当于用键盘输入 ctrl-z 来暂停一个进行的运行 |
可以使用 kill 或 killall 把信号传递给进程
# kill -signal PID
kill 可以将信号传递给某个工作(%jobnumber) 或某个 PID
# 范例 1:以 ps 找出 rsyslogd 这个进程 PID 后,再使用 kill 传递信号,让它可以重新读取配置文件
[root@study ~]# ps aux | grep 'rsyslogd'
root 1273 0.0 0.3 215672 3728 ? Ssl 21:15 0:00 /usr/sbin/rsyslogd -n
root 18876 0.0 0.0 9096 928 pts/0 RN+ 23:30 0:00 grep --color=auto rsyslogd
[root@study ~]# ps aux | grep 'rsyslogd' | grep -v 'grep'
root 1273 0.0 0.3 215672 3728 ? Ssl 21:15 0:00 /usr/sbin/rsyslogd -n
[root@study ~]# ps aux | grep 'rsyslogd' | grep -v 'grep' | awk '{print $2}'
1273
# 最终的指令是如下的
[root@study ~]# kill -SIGHUP $(ps aux | grep 'rsyslogd' | grep -v 'grep' | awk '{print $2}')
# 是否重启无法看通过看进程来知道,可以看日志
[root@study ~]# tail -5 /var/log/messages
Mar 9 23:20:01 study systemd: Removed slice User Slice of root.
Mar 9 23:30:01 study systemd: Created slice User Slice of root.
Mar 9 23:30:01 study systemd: Started Session 19 of user root.
Mar 9 23:30:01 study systemd: Removed slice User Slice of root.
Mar 9 23:35:20 study rsyslogd: [origin software="rsyslogd" swVersion="8.24.0-38.el7" x-pid="1273" x-info="http://www.rsyslog.com"] rsyslogd was HUPed
# 看上面,rsyslogd was HUPed 的字样,表示有重新启动
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
还记得可以查询到登录的 bash 的进程吗?也可以使用 kill -9 来删除,就意味着,该登陆者被踢下线了
# killall -signal 指令名称
由于 kill 后面必须要加上 PID (或是 job number),所以通常需要配合 ps、pstree 等指令,还可以使用另外一种方法来达到效果
killall [-iIe] [command name]
选项与参数:
-i:interactive ,交互式的,若需要删除时,会出现提示字符给用户确认
-e:exact,后面接的 command name 要一致,但整个完整的指令不能超过 15 个字符
-I:指令名称(可能含参数)忽略大小写
2
3
4
5
6
# 范例 1:给予 rsyslogd 指令启动的 PID 一个 SIGHUP 的信号
[root@study ~]# killall -1 rsyslogd
# 这里 -1 是信号
# 范例 2:强制终止所有以 httpd 启动的进程(其实当前没有该进程启动)
[root@study ~]# killall -9 httpd
httpd: no process found
# 范例 3:依次询问每个 bash 程序是否需要被终止
[root@study ~]# killall -i -9 bash
Signal bash(7780) ? (y/N) n
Signal bash(7835) ? (y/N) n
Signal bash(9051) ? (y/N) n
bash: no process found
# 这里都选择了 n,所以提示没有进程被找到,按下 y 就杀掉了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 关于进程的执行熟悉怒
CPU 是切换着执行进程,那么谁先执行?这个就要看进程的优先级 priority 与 CPU 排程(每个进程被 CPU 运行的演算规则)
# Priority 与 Nice 值
CPU 一秒钟可以运行达 G 的微指令次数,通过核心的 CPU 排程可以让各进程被 CPU 切换运行,因此每个进程在一秒钟内活多或少都会被 CPU 执行部分的脚步。
如果进程不分优先级顺序的话,那么就是排队执行,如果中间有个进程执行时间很长,其他进程就要等待很长时间
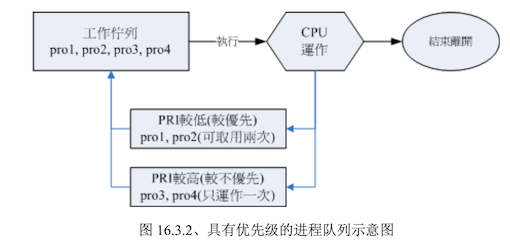
如上图,有了优先级之后,高优先级的可用被执行两次,低优先级则执行 1 次,但是上图仅是示意图,并非高优先级的就会执行两次,Linux 给予进程一个优先执行序(priority PRI),PRI 值越低优先级越高,不过该值是由核心动态调整的,用户无法直接调整 PRI 值
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 R 0 7183 9051 0 90 10 - 12406 - pts/0 00:00:00 ps
4 S 0 8985 7780 0 80 0 - 57972 do_wai pts/0 00:00:00 su
4 S 0 9051 8985 0 90 10 - 29118 do_wai pts/0 00:00:00 bash
2
3
4
5
由于 PRI 是动态调整的,用户无法干涉,但是可以通过 Nice 值来达到一定的优先级调整,Nice 就是上述中的 NI 值,一般来说 PRI 与 NI 的相关性 PRI(new)=PRI(old)+nice,虽然可以调整 nice 的值,由于 PRI 是动态调整的,所以不包装调整完之后,最终的 PRI 就会变低,优先级变高的
此外,必须要注意,nice 值范围
- nice 值范围是 -20~19
- root 可随意调整自己或他人进程的 Nice 值,且范围为 -20~19
- 一般使用者仅可调整自己进程的 Nice 值,且范围仅为 0~19(避免一般用户抢占系统资源)
- 一般使用者仅可将 nice 值越调越高;比如 nice 为 5,则未来仅能调整到大于 5;
那么调整 nice 值有两种方式:
- 一开始执行程序就立即给予一个特定的 nice 值:用 nice 指令
- 调整某个已经存在的 PID 的 nice 值:用 renice 指令
# nice:新执行的指令给予新的 nice 值
nice [-n 数字] command
-n:后面接一个数值,数值范围 -20~19
2
3
# 范例 1: 用 root 给一个 nice 值为 -5,用于执行 vim,并观察该进程
[root@study ~]# nice -n -5 vim &
[2] 30185
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 8985 7780 0 80 0 - 57972 do_wai pts/0 00:00:00 su
4 S 0 9051 8985 0 90 10 - 29118 do_wai pts/0 00:00:00 bash
4 T 0 30185 9051 0 85 5 - 10791 do_sig pts/0 00:00:00 vim
0 R 0 30652 9051 0 90 10 - 12407 - pts/0 00:00:00 ps
# 原本的 bash PRI 为 90,所以 vim 预设为 90,这里给予 nice -5,所以最终 PRI 变成了 85
# 要注意:不一定正好变成 85,因为会动态调整的
2
3
4
5
6
7
8
9
10
11
12
那么通常什么时候需要将 nice 值调大呢?比如:系统的背景工作中,某些比较不重要的进程进行时,比如备份工作,由于备份工作相当耗系统资源,这个时候就可以将备份的指令 nice 值调大一些,可以使系统的资源分配更公平
# renice:已存在进程的 nice 重新调整
renice [number] PID
# 范例 1:找出自己的 bash PID ,并将该 PID 的 nice 调整到 -5
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 3426 3372 0 80 0 - 58072 do_wai pts/1 00:00:00 su
4 S 0 3443 3426 0 80 0 - 29059 do_wai pts/1 00:00:00 bash
0 R 0 3487 3443 0 80 0 - 12407 - pts/1 00:00:00 ps
[root@study ~]# renice -5 3443
3443 (process ID) old priority 0, new priority -5
[root@study ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 3426 3372 0 80 0 - 58072 do_wai pts/1 00:00:00 su
4 S 0 3443 3426 0 75 -5 - 29059 do_wai pts/1 00:00:00 bash
0 R 0 3493 3443 0 75 -5 - 12407 - pts/1 00:00:00 ps
2
3
4
5
6
7
8
9
10
11
12
13
14
# 系统资源的观察
top 可以看到很多系统的资源使用情况,还有其他工具
# free:观察内存使用情况
free [-b|-k|-m|-g|-h] [-t] [-s N -c N]
选项与参数:
-b:单位参数;默认是用 k,其他单位对应 bytes、Mbytes、Kbytes、Gbytes
-t: 输出的最终结果,显示物理内存与 swap 的总量
-s:可以让系统每几秒输出一次,不间断输出;
-c:与 -s 同时处理,让 free 列出几次
2
3
4
5
6
7
# 范例 1:显示目前系统的内存容量
[root@study ~]# free -m
# 总内存 已使用 剩余 可用
total used free shared buff/cache available
Mem: 7631 713 6374 15 542 6671
Swap: 4095 0 4095
2
3
4
5
6
7
shared buff/cache 是缓冲区等使用量,available 是可用容量,当系统忙碌时,可以被释放掉,给系统使用
由于系统会把空闲内存拿来做缓冲区之用,所以你系统没有那么繁忙的时候,也会显示内存被用的多的原因,这个是正常的,需要注意的是 swap,swap 最好不要被使用,而且不要使用超过 20% 以上,因为 swap 被使用,那么很有可能是物理内存不够用了
# uname:查询系统与核心相关信息
uname [-asrmpi]
选项与参数:
-a:所有系统相关的,都列出来
-s:系统核心名称
-r:核心的版本
-m:本系统的硬件名称,例如 i686 或 x86_64
-p:CPU 的类型,与 -m 类似
-i:硬件的平台(ix86)
2
3
4
5
6
7
8
9
# 范例 1:输出系统的基本信息
[root@study ~]# uname -a
# 核心名称 主机名 核心版本 核心建立日期 与 硬件平台
Linux study.centos.mrcode 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
2
3
4
# uptime:观察系统启动时间与工作负载
[root@study ~]# uptime
17:31:46 up 43 min, 2 users, load average: 0.00, 0.01, 0.05
# 当前时间 已开机多久 几个用户登录 平均负载:1、5、15 分钟的平均负载
2
3
# netstat:追踪网络或插槽文件
该指令常被用在网络的监控方面;netstat 基本上的输出分为两大部分:网络与系统自己的进程相关性部分
netstat -[atunlp]
选项与参数:
-a:将目前系统上所有的联机、监听、Socket 数据都列出来
-t:列出 tcp 网络封包的数据
-u:列出 udp 网络封包的数据
-n:不以进程的服务名称,以端口号来显示
-l:列出目前正在网络监听的(listen)的服务
-p:列出该网络服务的进程 PID
2
3
4
5
6
7
8
9
# 范例 1:列出目前系统上已经建立的网络连接与 unix socket 状态
[root@study ~]# netstat
Active Internet connections (w/o servers) # 与网络相关部分
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 36 study.centos.mrcode:ssh 192.168.4.170:50821 ESTABLISHED
Active UNIX domain sockets (w/o servers) # 与本机的进程自己的相关性(非网络)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ] DGRAM 12644 /run/systemd/shutdownd
unix 3 [ ] DGRAM 7618 /run/systemd/notify
unix 2 [ ] DGRAM 7620 /run/systemd/cgroups-agent
unix 5 [ ] DGRAM 7634 /run/systemd/journal/socket
2
3
4
5
6
7
8
9
10
11
12
网络联机部分:
- Proto:网络封包协议,主要分为 TCP 与 UDP。
- Recv-Q:非由用户程序连接到此 socket 的复制和总 Bytes 数
- Send-Q:非由远程主机传送过来的 acknowledged 总 Bytes 数
- Local Address:本地端的 Ip:port
- Foreign Address:远程主机的 IP:port
- State:联机状态,主要有建立(ESTABLISED)、监听(LISTEN)
上面有一条数据,含义是:192.168.4.170:50821 通过 TCP 封包联机到本机端的 study.centos.mrcode:ssh,状态是 ESTABLISHED;至于更多的知识点这里不深入,在服务器篇讲解
除了网络上的联机之外,Linux 系统上的进程是可以接收不同进程所发来的信息,通过 socket file 可以在两个进程之间通信。比如 X Window 这种需要通过网络连接的软件,新版 distribution 以 socket 来进行窗口接口的联机沟通。上表中 socket file 的输出字段含义为:
- Proto:一般是 unix
- RefCnt:连接到此 socket 的进程数量
- Flags:联机旗标
- Type:socket 存取的类型。主要有 STREAM:确认联机、DGRAM:不需确认 两种
- State:若为 CONNECTED 表示多个进程之间已经联机建立
- PATH:连接到此 socket 的相关程序路径,或则是相关数据输出的路径
# 范例 2:找出目前系统上已在监听的网络联机与 PID
[root@study ~]# netstat -tulnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1380/cupsd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1579/master
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 3765/sshd: mrcode@p
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 1973/dnsmasq
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1379/sshd
tcp6 0 0 ::1:631 :::* LISTEN 1380/cupsd
tcp6 0 0 ::1:25 :::* LISTEN 1579/master
tcp6 0 0 ::1:6010 :::* LISTEN 3765/sshd: mrcode@p
tcp6 0 0 :::111 :::* LISTEN 1/systemd
tcp6 0 0 :::22 :::* LISTEN 1379/sshd
udp 0 0 192.168.122.1:53 0.0.0.0:* 1973/dnsmasq
udp 0 0 0.0.0.0:67 0.0.0.0:* 1973/dnsmasq
udp 0 0 0.0.0.0:111 0.0.0.0:* 1/systemd
udp 0 0 127.0.0.1:323 0.0.0.0:* 938/chronyd
udp 0 0 0.0.0.0:41378 0.0.0.0:* 953/avahi-daemon: r
udp 0 0 0.0.0.0:672 0.0.0.0:* 927/rpcbind
udp 0 0 0.0.0.0:5353 0.0.0.0:* 953/avahi-daemon: r
udp6 0 0 :::111 :::* 1/systemd
udp6 0 0 ::1:323 :::* 938/chronyd
udp6 0 0 :::672 :::* 927/rpcbind
# 最后一个字段是 PID 与进程的指令名称
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 范例 3:将上述的 0 0.0.0.0:41378 网络服务关闭
[root@study ~]# kill -9 953
[root@study ~]# killall -9 avahi-daemon
2
3
对于非正常的关闭服务方法就用暴力的 kill -9,正常的关闭方式,下个章节讲解
# dmesg:分析核心产生的信息
系统在开机的时候,核心会去侦测系统的硬件,那么硬件的检测信息由于开机过程中要么一闪而过,要么没有显示在屏幕上,可以使用 dmesg 来查看
从系统开机起,核心产生的信息都会记录到内存中,通过 dmesg 可以查询到,信息过多时可以通过 more 指令查看
# 范例 1:输出所有的核心开机时的信息
[root@study ~]# dmesg | more
[ 0.000000] Initializing cgroup subsys cpuset
[ 0.000000] Initializing cgroup subsys cpu
[ 0.000000] Initializing cgroup subsys cpuacct
[ 0.000000] Linux version 3.10.0-1062.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.5 20150623 (Red Hat
4.8.5-36) (GCC) ) #1 SMP Wed Aug 7 18:08:02 UTC 2019
[ 0.000000] Command line: BOOT_IMAGE=/vmlinuz-3.10.0-1062.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto spect
re_v2=retpoline rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet LANG=zh_CN.UTF-8
[ 0.000000] e820: BIOS-provided physical RAM map:
[ 0.000000] BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
[ 0.000000] BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
[ 0.000000] BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
--More--
# 范例 2:找到硬盘相关信息
[root@study ~]# dmesg | grep -i 'sda'
[ 2.632630] sd 2:0:0:0: [sda] 85491712 512-byte logical blocks: (43.7 GB/40.7 GiB)
[ 2.632651] sd 2:0:0:0: [sda] Write Protect is off
[ 2.632653] sd 2:0:0:0: [sda] Mode Sense: 00 3a 00 00
[ 2.632662] sd 2:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
[ 2.643988] sda: sda1 sda2 sda3 sda4 sda5 sda6 sda7 sda8
[ 2.644394] sd 2:0:0:0: [sda] Attached SCSI disk
[ 4.616881] XFS (sda2): Mounting V5 Filesystem
[ 4.636376] XFS (sda2): Ending clean mount
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# vmstat:侦测系统资源变化
vmstat 可以侦测 CPU、内存、磁盘输入输出状态等信息。比如可以了解一台繁忙的系统到底是哪个环节最耗时间,可以使用 vmstat 分析看看,常见选项与参数如下:
vmstat [-a] [延迟 [总计侦测次数]] # CPU/内存等信息
vmstat [-fs] # 内存相关
vmstat [-S 单位] # 设置显示数据的单位
vmstat [-d] # 与磁盘有关
vmstat [-p 分区槽] # 与磁盘有关
选项与参数:
-a:使用 inactive/active(是否活跃)取代 buffer/cache 的内存输出信息
-f:开机到目前为止,系统复制(fork)的进程数
-s:将一些事件(开机到目前为止)导致的内存变化情况列表说明
-S:后面可以接单位,例如 k、M 等
-d:列出磁盘的读写总量统计表
-p:后面列出分区槽,可显示该分区槽的读写总量统计表
2
3
4
5
6
7
8
9
10
11
12
13
# 范例 1:统计目前主机 CPU 状态,每秒一次,总共 3 次
[root@study ~]# vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 450296 2116 346828 0 0 501 36 181 320 2 3 95 0 0
0 0 0 450156 2116 346860 0 0 0 0 163 223 2 3 95 0 0
0 0 0 450156 2116 346860 0 0 0 0 273 388 3 5 91 0 0
2
3
4
5
6
7
8
还可以不限制次数,就一直统计字段说明如下:
procs:进程
- r:等待运行中的进程数量
- b:不可被唤醒的进程数量
rb 越多表示系统越繁忙。因为系统太忙,导致很多进程无法被执行或一直在等待而无法被唤醒
memory:内存
- swpd:虚拟内存被使用的容量
- free:未被使用的内容容量
- buff:用于缓冲存储器
- cache:用于高速缓存
这里的含义与 free 指令一致
swap:内存交换空间
- si:由磁盘中将进程取出的量
- so:由于内存不足而将没用到的进程写入到磁盘的 swap 的容量
如果 si、so 的数值太大,表示内存的数据常常得在磁盘与主存储器之间传来传去,效率很低
io:磁盘读写
- bi:由磁盘读入的区块数量
- bo:写入到磁盘去的区块数量
如果这部分数值越高,代表系统的 I/O 非常忙碌
system:系统
- in:每秒被中断的进程次数
- cs:每秒钟进行的事件切换次数
这两个值越大,代表系统与接口设备的沟通非常频繁,接口设备包括磁盘、网卡、时钟等
CPU:
- us:非核心层的 CPU 使用状态
- sy:核心层所使用的 CPU 状态
- id:闲置的状态
- wa:等待 I/O 所耗费的 CPU 状态
- st:被虚拟机(virtual machine)所盗用的 CPU 使用状态(2.6.11)
练习机上看不到忙碌的数据,如果有一天,你的系统非常忙碌,可以使用该指令来分析是哪里出现了问题
# 范例 2:系统上面所有的磁盘读写状态
[root@study ~]# vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
sda 7640 1 709893 6377 2486 351 54323 8478 0 5
sdb 116 0 5384 27 0 0 0 0 0 0
sr0 0 0 0 0 0 0 0 0 0 0
dm-0 7072 0 661717 6054 2611 0 45902 10871 0 5
dm-1 88 0 4408 21 0 0 0 0 0 0
dm-2 103 0 10834 58 23 0 4325 56 0 0
2
3
4
5
6
7
8
9
10
11
至于上面的字段含义,可以通过 man vmstat 查阅