
# 111. 缓存雪崩的基于事前+事中+事后三个层次的完美解决方案
相对来说,考虑的比较完善的一套方案,分为事前、事中、事后三个层次去思考再怎么来应对缓存雪崩的场景
对于解决方案,再次强调一下,这个需要有上下文的,本课程的方案基本上就是基于本课程的缓存架构方案来讲解的
通过下面的架构图,来分析具体的方案内容
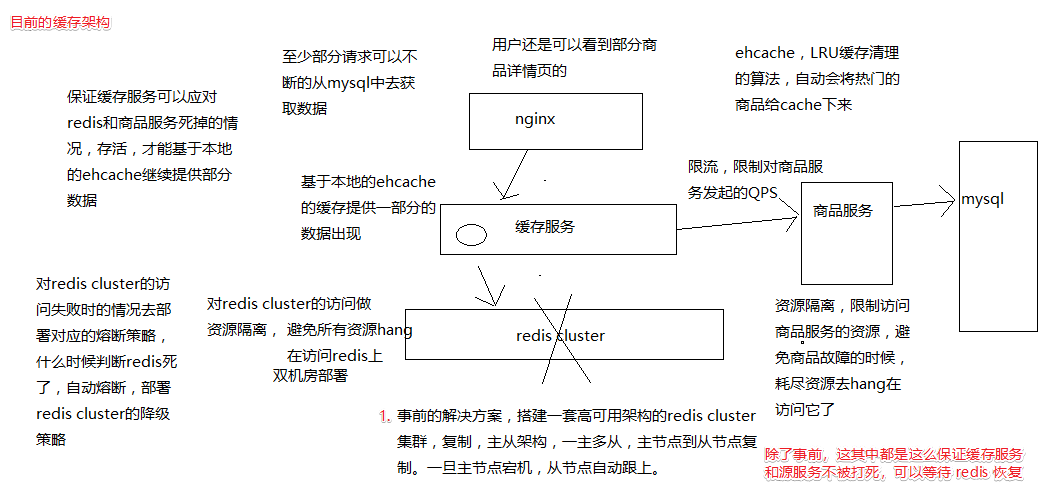
# 事前解决方案
发生缓存雪崩之前,事情之前,怎么去避免 redis 彻底挂掉
redis本身的高可用性、复制、主从架构,操作主节点,读写,数据同步到从节点,一旦主节点挂掉,从节点跟上
双机房部署,一套 redis cluster,部分机器在一个机房,另一部分机器在另外一个机房
还有一种部署方式,两套 redis cluster,两套 redis cluster 之间做一个数据的同步,redis 集群是可以搭建成树状的结构的
对于这种方式,没有明白怎么做数据同步?
一旦说单个机房出了故障,至少说另外一个机房还能有些 redis 实例提供服务
# 事中解决方案
redis cluster 已经彻底崩溃了,已经开始大量的访问无法访问到 redis 了
# ehcache 本地缓存
所做的多级缓存架构的作用上了 ,ehcache 的缓存应对零散的 redis 中数据被清除掉的现象,另外一个主要是预防 redis 彻底崩溃
多台机器上部署的缓存服务实例的内存中,还有一套 ehcache 的缓存,还能支撑一阵
# 对 redis 访问的资源隔离
对 redis 访问使用 hystrix 进行隔离,防止自己资源大量阻塞在访问 redis 上
# 对源服务访问的限流以及资源隔离
同上,防止自己资源大量阻塞在访问源服务上,同时 hystrix 在资源隔离时也做到了限流
# 事后解决方案
- redis 数据可以恢复,之前讲解过各种备份机制,redis 数据备份和恢复,redis 重新启动起来
- redis 数据彻底丢失了或者数据过旧,快速缓存预热,redis 重新启动起来
由于事中做了限流与隔离,缓存服务不会被打死,通过熔断策略 和 half-open 策略, 可以自动可以恢复对 redis 的访问,发现 redis 可以访问了,就自动恢复了
# 小结
基于 hystrix 的高可用服务这块技术之后,先讲解缓存服务如何设计成高可用的架构
缓存架构应对高并发下的缓存雪崩的解决方案,基于 hystrix 去做缓存服务的保护
要带着大家去实现的有什么东西?事前和事后不用了吧,事中 ehcache 本身也做好了
基于 hystrix 对 redis 的访问进行保护,对源服务的访问进行保护,讲解 hystrix 的时候, 也说过对源服务的访问怎么怎么进行这种高可用的保护
但是站的角度不同,源服务如果自己本身不知道什么原因出了故障,我们怎么去保护,调用商品服务的接口大量的报错、超时
总的来说就是:限流、资源隔离、降级 保证缓存服务不能死掉,同时快速恢复 redis cluster