
# 014. redis 如何通过读写分离来承载读请求 QPS 超过 10 万 +?
# redis 高并发跟整个系统的高并发之间的关系
搞高并发的话,不可避免的要把底层的缓存搞得很好,这里就是 redis
使用 mysql 来支撑高并发的话,就算做到了,那么也是通过一系列复杂的分库分表方案。订单系统中是有事务要求的,QPS 到几万,就已经比较高了,很难提升上去了
要做一些电商的商品详情页,真正的超高并发,QPS 上十万,甚至是百万,一秒钟百万的请求量
光是 redis 是不够的,但是 redis 是整个大型的缓存架构中,支撑高并发的架构里面,非常重要的一个环节
首先,你的底层的缓存中间件,缓存系统,必须能够支撑的起我们说的那种高并发,其次,再经过良好的整体的缓存架构的设计(多级缓存架构、热点缓存),支撑真正的上十万,甚至上百万的高并发
# redis 不能支撑高并发的瓶颈在哪里?
就是 单机
单机 redis 一般情况下能够承载的 QPS 上万到几万不等,根据你的业务操作的复杂性, redis 提供很多复杂的操作,如 lua 脚本等复杂的操作,那么可能会更低。 比如就简单的 kv 查询来说还是比较容易达到上万的。
假设有上千万、上亿的用户来访问,直接就能把你的单机 redis 干死
# 如果 redis 要支撑超过 10万+ 的并发,那应该怎么做?
单机的 redis 几乎不太可能 QPS 超过 10万+,除非一些特殊情况,比如你的机器性能特别好,配置特别高,真实物理机,维护做的特别好,而且你的整体的操作不是太复杂
单机在一般就几万。要提高并发,一般的方案是 读写分离,一般来说,对缓存,一般都是用来支撑读高并发的,写的请求是比较少的,可能写请求也就一秒钟几千,一两千,大量的请求都是读,一秒钟二十万次读
也就是 读多写少 的情况下才能用缓存。写多读少可以选择使用异步写,本课程主要讲解缓存
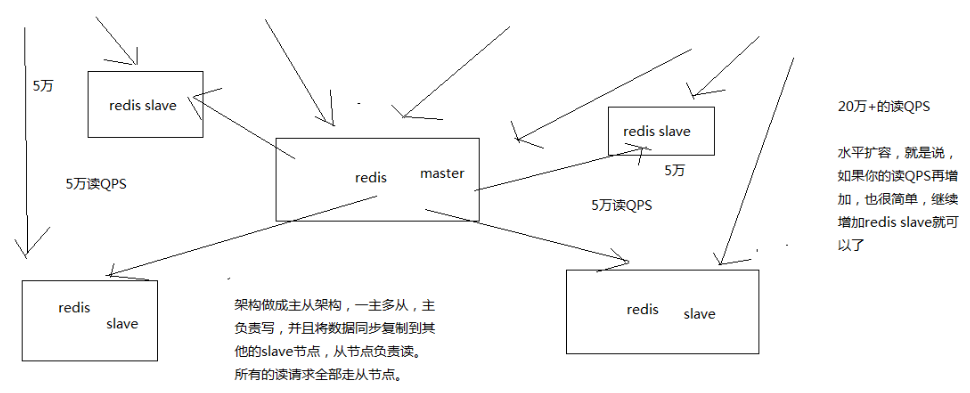
如上图,一主多从,主负责写,并且将数据同步复制到其他 slave 节点,从节点负责读,还可水平扩展 slave 节点以支撑更多的 QPS
主从架构 -> 读写分离 -> 支撑 10万+ 读 QPS 的架构
接下来要讲解的就是怎么实现 redis 的主从架构。