# 图解写一致性原理以及 quorum 机制深入剖析
# consistency 写一致性
我们在发送任何一个增删改操作的时候,比如说 put /index/type/id,
都可以带上一个 consistency 参数,指明我们想要的写一致性是什么?
put /index/type/id?consistency=quorum
有三个可选
one(primary shard)
要求我们这个写操作,只要有一个 primary shard 是 active 活跃可用的,就可以执行
all(all shard)
要求我们这个写操作,必须所有的 primary shard 和 replica shard 都是活跃的,才可以执行这个写操作
quorum(default)
默认的值,要求所有的 shard中,必须是大部分的 shard 都是活跃的,可用的,才可以执行这个写操作
# quorum 机制
写之前必须确保大多数 shard 都可用,当 number_of_replicas>1 时才生效
计算公式:quorum = int( (primary + number_of_replicas) / 2 ) + 1,
举个例子:3个 primary shard,number_of_replicas=1,总共有 3 + 3 * 1 = 6个 shard
quorum = int( (3 + 1) / 2 ) + 1 = 3
所以,要求 6个 shard中至少有 3个shard 是 active 状态的,才可以执行这个写操作
如果节点数少于quorum数量,可能导致quorum不齐全,进而导致无法执行任何写操作
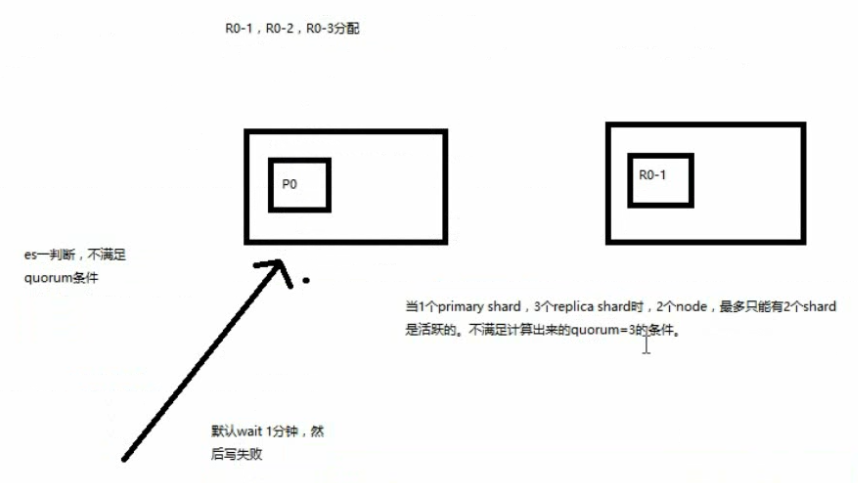
3个 primary shard,replica=1,要求至少 3个 shard 是 active,3个 shard 按照之前学习的 shard&replica机制,必须在不同的节点上,如果说只有 2台 机器的话,是不是有可能出现说,3个 shard 都没法分配齐全,此时就可能会出现写操作无法执行的情况
es 提供了一种特殊的处理场景,就是说当 number_of_replicas>1 时才生效,因为假如说,你就一个 primary shard,replica=1,此时就 2个 shard
(1 + 1 / 2) + 1 = 2,要求必须有 2个 shard 是活跃的,但是可能就 1个 node,此时就 1个 shard是活跃的,如果你不特殊处理的话,导致我们的单节点集群就无法工作
疑问
p 和 r 不能在相同机器上。但是 r 和 r 也不能吗? p 和 p 可以再同一台机器上,现在是单节点,可以查看到他的健康状态 有 9个 p 被分配了,但是只有 3 个索引,也就是说一台机器上可以存在相同的 p ?
经过测试:在同一台机器上启动两个 es 实例,9 个 pri 和 9 个 rep,都可以被完全分配,集群状态变为 green
GET _cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1546783226 22:00:26 elasticsearch green 2 2 18 9 0 0 0 0 - 100.0%
GET _cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open ecommerce ZpGp7bIBQBaZFk9SYmbJVQ 5 1 4 0 44.5kb 22.2kb
green open test_index g4RJx2v8TXK95LdwlhRx5A 3 1 8 0 56.5kb 28.2kb
green open .kibana id1SV_oGSjyGosKxeJApww 1 1 1 0 6.3kb 3.1kb
2
3
4
5
6
7
8
9
10