
# 分布式搜索引擎内核解密之 query phase
# query phase
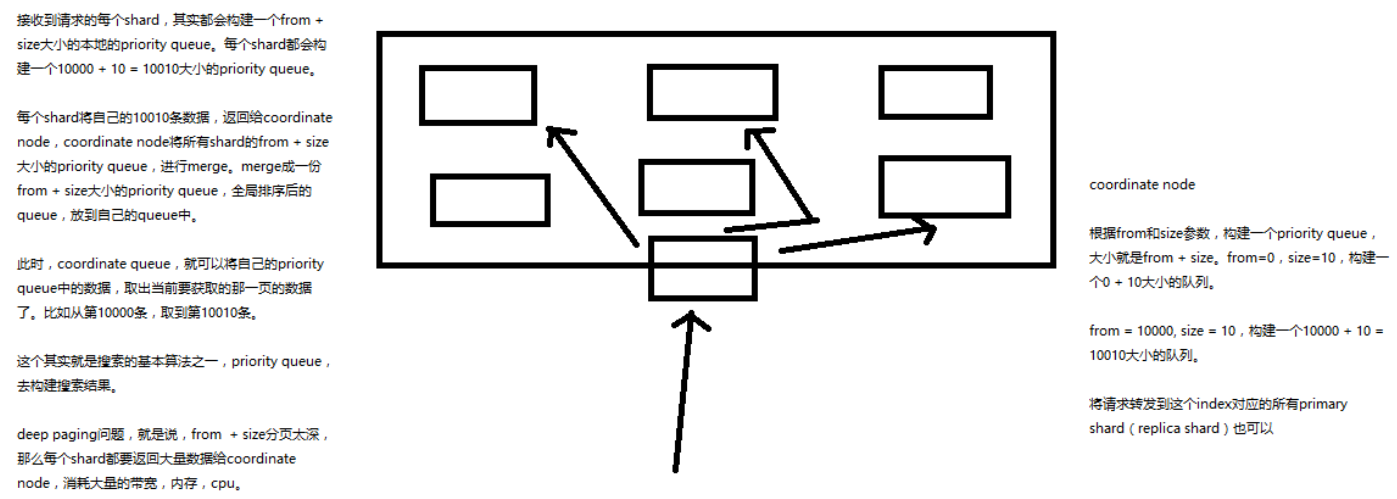
- 搜索请求发送到某一个 coordinate node,构构建一个 priority queue,长度以 paging 操作 from 和 size 为准,默认为 10
- coordinate node 将请求转发到所有 shard,每个 shard 本地搜索,并构建一个本地的 priority queue
- 各个 shard 将自己的 priority queue 返回给 coordinate node,并构建一个全局的 priority queue
这个流程就叫 query phase (查询阶段)
TIP
这个过程还是经典的做法,有一个节点来做聚合,所以就会有单节点聚合占用资源过多的情况发生
# replica shard 如何提升搜索吞吐量
一次请求要打到所有 shard 的一个 replica/primary 上去,如果每个 shard 都有多个 replica,那么同时并发过来的搜索请求可以同时打到其他的 replica 上去
疑问
还是同步问题,这个还是不知道 es 是怎么保证在快速同步的,并且查询还没有问题的?不明白
因为请求分发到shard的时候是选择“一套”, 譬如:3个primary shard, 1个replica; ASR算法选择3(1个p+2个r; 3个p等等)个所谓的最优shard, 当增加replica的数量,那么“一套“选择的余地就增加了, 之前总共的3个shard只能是在总共6个shard里面选择, 现在可以在更多了shard里面选择3个; 加入replica增加到3, 那么现在就可以在总共12个shard里面选择“一套”去执行查询,吞吐量自然是增加了