
# 064. 大白话讲并行度和流分组
对于 java 工程师来说,先不说精通 storm ,本教程希望达到的一个效果如下:
对 storm 的核心的基本原理要清楚:集群架构、核心概念、并行度和流分组
掌握最常见的 storm 开发范式
spout 消费 kafka,后面跟一堆 bolt,bolt 之间设定好流分组的策略, bolt 中填充各种代码逻辑
了解如何将 storm 拓扑打包后提交到 storm 集群上去运行
掌握如何能够通过 storm ui 去查看你的实时计算拓扑的运行现状
如果你所在公司有大数据团队并且维护了一个 storm 集群,那么掌握如何开发和部署即可, 如果没有,那么你就需要去深入学习下 storm 了。如果你的场景不是特别复杂, 整个数据量也不是特别大,其实自己主要研究一下,怎么部署 storm 集群也可以,本教程也会讲解
Storm 的并行度以及流分组是重要的一个概念,但是没有几个人能说的清楚。
好多年前,我第一次接触 storm 的时候,真的我觉得都没几个人能彻底讲清楚,用一句话讲清楚什么是并行度,什么是流分组, 很多时候,你以外你明白了,其实你不明白,比如我经常面试一些做过 storm 的人过来,我就问一个问题, 就知道它的水深水浅,流分组的时候,数据在 storm 集群中的流向,你画一下,比如你自己随便设想一个拓扑结果出来, 几个 spout,几个 bolt,各种流分组情况下,数据是怎么流向的,要求具体画出集群架构中的流向, worker,executor,task,supervisor,数据是怎么流转的;几乎没几个人能画对,为什么呢, 很多人就没搞明白这个并行度和流分组到底是什么
那么这里一句话总结:
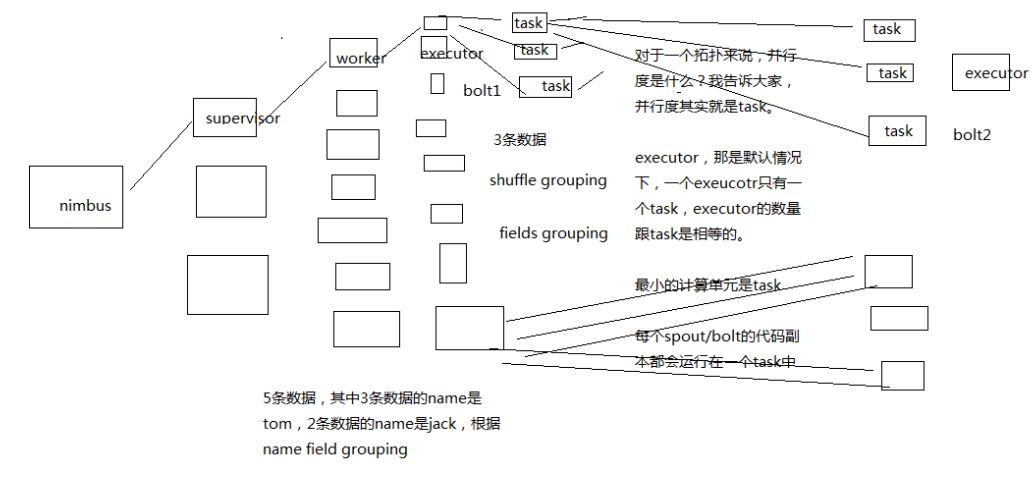
并行度:Worker->Executor->Task,没错,是 Task
默认情况下,一个 Executor 对应一个 Task
简单说就是 task 越多,并行度越高
流分组:Task 与 Task 之间的数据流向关系
一个拓扑中,可以有很多 Spout + Bolt,那么 bolt1 的数据流向 bolt2 的时候的一个策略 就是流分组
流分组策略:
Shuffle Grouping:随机发射,负载均衡
Fields Grouping:根据一个或多个字段进行分组
那一个或者多个 fields 如果值完全相同的话,那么这些 tuple,就会发送给下游 bolt 的其中固定的一个 task
你发射的每条数据是一个 tuple,每个 tuple 中有多个 field 作为字段
比如 tuple 3 个字段,name,age,salary
{"name": "tom", "age": 25, "salary": 10000}-> tuple -> 3个 field,name,age,salaryAll Grouping:广播分发
Global Grouping:选择其中一个 task 最小的 id 分发
None Grouping:与 shuffle 类似
Direct Grouping:指定一个 task id 发送
Local or Shuffle Grouping: 只在本地同一个进程(worker)中国随机分发
最常用的是前两种