
# 105. 生产环境中的线程池大小以及 timeout 超时时长优化经验总结
在生产环境里面,一个线程池的大小和 timeout 时长怎么设置?如果设置不合理问题还是很大的
# 优化配置流程
有两种方案:
- 一上来就设置大一点,然后再逐步优化降低
- 一上来就默认配置,然后再逐步优化
这里讲解使用默认值方式,再逐步优化的流程
一开始先不要设置 tomeout 超时时长,默认就是 1000ms(1s)
一开始先不要设置线程池大小,默认就是 10
直接部署到生产环境,如果运行良好,那么就不用管了
依赖标准的监控和报警机制来捕获到系统的异常运行情况(观察 24 小时)
根据调用延迟的占比、流量来计算出让断路器生效的最小配置数值
可以通过 hystrix 配置进行热修改,然后继续在 hystrix dashboard 上监控
监控在后面章节会讲解,但是这个热修改不知道后面有没有, 前面的章节热修改只提到过等待队列的热修改,但是还有限制。
通过以上步骤循环观察,知道调优到最佳
# 优化经验
假设对一个依赖服务的高峰调用 QPS 是每秒 30 次
默认线程池大小为 10 每秒高峰访问次数 * 99% 的访问延时 + 队列 buffer = 30 * 0.2 + 4 = 10 线程
也就是说,99 % 的访问都在 200 毫秒(0.2 秒)内响应;每个线程 1 秒钟处理 3 个线程;
3 * 200 = 600 毫秒;但是别忘记了,还有队列中等待的时间,一个线程先执行,最后一个线程最长会等待 400 毫秒时间
超时时间:按照 99.5% 的访问延时时间进行设置
一次访问 200 毫秒内响应(TP99 如果是 200 ms),再加一次重试时间,为 300 毫秒
疑问:那么理想的超时时间是 400 毫秒(上面已经说过,加上等待时间),但是这里感觉又不对, 假如是 400 毫秒,都超时那么低三个线程将会超过 1 秒钟,导致 1 秒钟内处理不了 3 个线程。 下一秒就会有另外的 30 个线程进来,就会导致线程池已满,部分线程就直接被 reject 了
所以这第一步计算线程公司是不是就有问题?
总之,这里的意思就是要让 1 秒内所有的线程都能执行完,根据并发计算到的数量;
那么线程大小和超时时间能导致什么情况出现呢?如下图
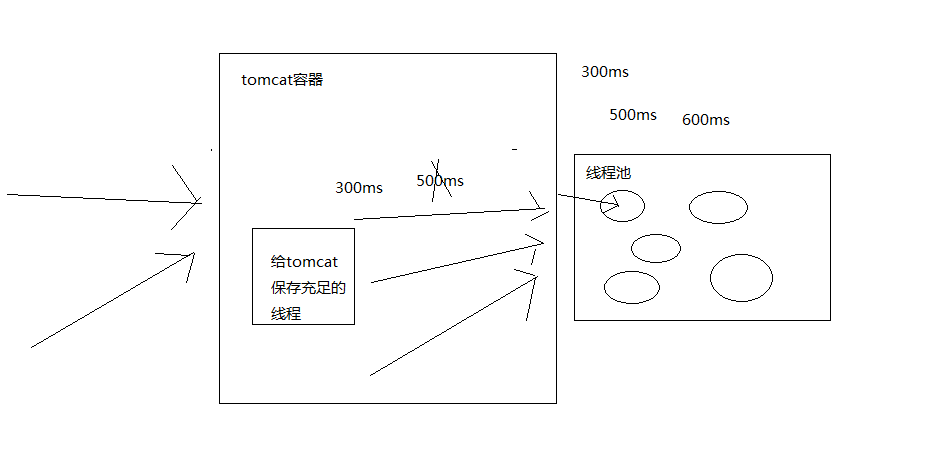
左侧为 tomcat 容器线程,右侧为 hystrix 线程池,如果设置的不合理, 将导致大量线程被阻塞在 hystrix 上,也就间接导致 tomcat 的线程被阻塞住, 这样就会导致 tomcat 没有更多的资源去处理其他的服务调用;
如果设置得合理,就算这个服务调用比较耗时,那么也只是这个服务被降级的多,很快就返回了, 并不会影响其他的服务资源调用
大家可能会想,每秒的高峰访问次数是 30 次,如果是 300 次,甚至是 3000 次、30000次呢? 30000 * 0.2 = 6000 + buffer = 6100,一个服务器内一个线程池给 6000 个线程, 这很恐怖的,如果你一个依赖服务占据的线程数量太多的话,会导致其他的依赖服务对应的线程池里没有资源可以用了, 因为一个 tomcat 总的并发数量是有限的。
那么在这种情况下,其实就需要更多的机器来支撑了。
你要真的说是,你的公司服务的用户量,或者数据量,或者请求量,真要是到了每秒几万的QPS,
30000QPS:60 * 3 = 1分钟 180万 访问量,一小时就按 1 亿计算,这个就很大了的量了; 用几十台服务器去支撑,我觉得很正常,一般 QPS 每秒在几千都算多的了